

バッチ処理とは、複数のプログラムやデータをまとめて一定の単位で実行する処理方式です。一連の処理(ジョブ)をあらかじめスケジュールし、自動的に実行します (バッチ処理 – うちでのこづち |業界トップクラス800社以上が使うEC・通販CRM/MAツール)。例えば**「夜間にまとめて実行される定期処理」が典型で、対となるリアルタイム処理が入力の都度すぐに処理・応答するのに対し、バッチ処理は決まったタイミングでまとめて実行されます。リアルタイム処理がイベント発生やユーザー操作を起点として即座に動くのに対し、バッチ処理は時間やデータ量などの条件に基づき定期的に動く**点が大きな違いです。
実行間隔にも違いがあります。リアルタイム処理は数秒~数分といった短い間隔で連続実行されるのに対し、バッチ処理は1日1回や月1回など比較的長い間隔で実行されます。たとえばATMでの残高照会やオンライン決済はリアルタイム処理で即座に結果が反映されますが、銀行の勘定系システムでは一日の終わりに全取引を集計する「夜間バッチ」を行い、それによって翌日に口座残高や利用明細が更新されるケースがあります (実は身近でも使われているバッチ処理、その概要について解説 | AIZINE(エーアイジン))。このように、即時性が求められる処理はリアルタイム方式で行い、大量データの集計や定期処理はバッチ方式で行うのが一般的です (リアルタイム処理とは?定義やメリット・デメリット、バッチ処理との違いも解説 | TROCCO®(トロッコ))。リアルタイム処理は即応性を重視する場面に適し、バッチ処理は効率重視で大量データを一括処理する場面に適していると言えます。



各業界におけるバッチ処理の活用事例
バッチ処理は様々な業界で重要な役割を果たしています。以下に金融、製造、小売、EC、医療といった各業界での代表的な活用例を表にまとめます。
| 業界 | バッチ処理の活用例 |
|---|---|
| 金融業界(銀行・保険など) | 日次・月次の大量取引処理:銀行では一日の終わりに全取引を集計する夜間バッチを実施します。クレジットカード会社では当月の利用明細をまとめて集計し、月次請求書を一括生成します (バッチ処理とは – 用途やメリット、課題について – TIBCO|NTTコム オンライン)。また、給与振込や企業間決済といった大規模送金も夜間バッチで処理されます ([実は身近でも使われているバッチ処理、その概要について解説 |
| 製造業界(メーカー等) | 生産計画・在庫の集約処理:製造業では毎日の生産実績データや在庫データを夜間に集計し、翌日の生産計画や発注計画に反映させます。例えば、日次の生産スケジュールを前夜のバッチで作成しておき、翌朝の工場稼働に備えるケースがあります(※もしバッチが遅延すると翌日の生産開始に影響が出るため注意が必要です)。また、工場設備から収集したセンサーデータを一定時間ごとにまとめて分析するのもバッチ処理の活用例です。 |
| 小売業界(店舗・通販) | 売上・在庫データの集計:小売店では各店舗のPOS売上データを一日に一度本部システムに集約し、日次売上レポートや在庫更新を行います。在庫管理システムでも一定期間ごとに在庫数を一括更新するバッチ処理が用いられます ([実は身近でも使われているバッチ処理、その概要について解説 |
| EC業界(オンライン通販) | データ連携・一括更新処理:ECサイトでは日中に蓄積したデータを深夜バッチで他システムと連携します。例えば**「カートシステムの顧客データを毎晩まとめてマーケティングツールへCSV連携し、顧客情報を最新化する」**といった処理が挙げられます (バッチ処理 – うちでのこづち |業界トップクラス800社以上が使うEC・通販CRM/MAツール)。また、終日受け付けた注文を一括で倉庫システムに渡す注文集約バッチや、商品価格の一括改定、レコメンデーション用データの夜間集計なども行われています。 |
| 医療業界(病院・医療保険) | 大量データの一括処理:医療分野でもバッチ処理は活用されています。例えば医療保険のレセプト(診療報酬請求)処理では、一日分の膨大な請求データをまとめて処理し、電子化された請求を保険者に送信します ([バッチ処理とは? バッチ処理のやり方、メリット、使用例を解説 |
上記のように、業界ごとの業務特性に合わせてバッチ処理が組み込まれています。金融では正確さと締め処理の厳守、小売やECではデータ連携や大量注文処理、医療では膨大な記録の集約など、それぞれバッチ処理が裏方で支えることで日々の業務が円滑に進んでいます。また、バッチ処理は基本的に人手を介さず自動実行されるため、一度仕組みを構築すれば大規模データ処理でも人為ミス無く安定して運用できる点が大きなメリットです (実は身近でも使われているバッチ処理、その概要について解説 | AIZINE(エーアイジン))。
バッチ処理の代表的な用途とメリット
バッチ処理は繰り返し発生する定常業務や、大量データを効率よく処理する用途で広く使われます。代表的な利用用途には以下のようなものがあります。
- 定期データ集計・レポート生成:一定期間の取引データを集計し、日次・月次の業績レポートを作成する。 (バッチ処理とは? – バッチ処理システムの説明 – AWS)例えば月末に1ヶ月分の売上データを集計して経営報告書を作る処理は典型的なバッチジョブです。人手で行うと膨大な時間がかかる集計作業も、バッチ処理なら短時間で正確にこなせます。
- 一括バッチ更新・バルク処理:データベースのレコードをまとめて更新したり、大量のファイルを一括変換・転送する処理。 (バッチ処理とは? バッチ処理のやり方、メリット、使用例を解説 | Talend)例えば数百万件のデータフォーマット変換や、全顧客に対する一斉メール送信、全商品の価格一括改定など、一度に大量のデータに処理を施すバルク処理はバッチが得意とするところです。
- 定期バッチ業務:毎日・毎週・毎月決まったスケジュールで必要となる業務。 (バッチ処理とは? – バッチ処理システムの説明 – AWS)例として、週次/月次の請求書発行や給与計算、サブスクリプションサービスの課金処理、定期バックアップがあります。これらはスケジュールに従い忘れず実行する必要があるため、バッチ処理とジョブスケジューラによる自動化が有効です。
- データエクスポート・インポート:他システムとの連携のためにデータを抽出・出力したり、受け取ったデータを取り込む処理。例えば毎日深夜に基幹DBから特定項目を抽出してデータレイクに格納する、あるいは外部システムから受領したファイルを読み込んでデータベース更新する、といった用途です。人が起きていない時間帯でもシステム間連携を進められるため、非稼働時間を活用した効率化につながります (バッチ処理とは? バッチ処理のやり方、メリット、使用例を解説 | Talend) (バッチ処理とは? バッチ処理のやり方、メリット、使用例を解説 | Talend)。
- バックアップ・アーカイブ:データのバックアップ取得やログのアーカイブもバッチ処理で定期実行する典型的な例です。例えば毎日深夜に増分バックアップを取得したり、一定期間ごとに古いログをまとめて圧縮保存するといった処理です。リアルタイム性は不要ですが確実性が求められるため、自動バッチで忘れなく実行することが重要です。
こうした用途にバッチ処理を用いることで、大量データ処理の効率化や人的コストの削減、処理ミスの低減が図れます。コンピュータリソースの余裕がある時間帯にまとめて処理できるため、システム全体の負荷平準化やコスト削減にも寄与します (バッチ処理とは – 用途やメリット、課題について – TIBCO|NTTコム オンライン) (バッチ処理とは? – バッチ処理システムの説明 – AWS)。実際、現代の企業でも**「一日の終わりに情報を更新する」「夜間に帳票をまとめて印刷する」**など、多くのビジネスプロセスでバッチアプリケーションが活用されています (バッチ処理とは? – バッチ処理システムの説明 – AWS)。
バッチ処理の技術的側面:コード例で見る仕組み
ここではバッチ処理の具体例として、簡単なコード例を紹介します。初心者にも分かりやすいよう、ファイル処理を行うバッチジョブを想定し、シェルスクリプトとPythonでの実装例を見てみましょう。
まずはシェルスクリプトによるバッチ処理の例です。例えば「あるフォルダ内のCSVファイルをすべてJSON形式に変換し、出力フォルダに保存する」バッチをシェルスクリプトで書くと以下のようになります。
#!/bin/bash
# CSVファイルをJSONに一括変換するバッチ処理例
INPUT_DIR="/data/csv"
OUTPUT_DIR="/data/json"
LOG_FILE="/data/batch.log"
echo "バッチ開始: $(date)" >> $LOG_FILE
# 入力ディレクトリ内のすべてのCSVに対して処理
for filepath in "$INPUT_DIR"/*.csv; do
filename=$(basename "$filepath" .csv)
# Pythonスクリプトを呼び出してCSV→JSON変換
python csv_to_json.py "$filepath" > "$OUTPUT_DIR/${filename}.json"
if [ $? -ne 0 ]; then
echo "Error: $filepath の変換に失敗" >> $LOG_FILE
else
echo "Success: $filepath を変換" >> $LOG_FILE
fi
done
echo "バッチ終了: $(date)" >> $LOG_FILE
上記のスクリプトでは、forループで入力ディレクトリ内のCSVファイルを順次処理し、Pythonスクリプト(csv_to_json.py)を呼び出してJSON形式に変換しています。処理の開始・終了時刻や成功・失敗をログファイルに記録している点にも注目してください。実際のバッチ運用ではこのようにログ出力を行うことで、処理結果やエラーを後から確認できるようにします (ウェブアプリケーション運用に必要な基本的なログについて)。
次にPythonスクリプト側の簡単な例を示します。こちらはCSVファイルを読み込んでJSONに変換する処理の中身をイメージしたものです。
import csv, json, sys
# コマンドライン引数で入力CSVファイルパスを受け取る
csv_path = sys.argv[1]
json_data = []
# CSVを読み込み各行を辞書型に変換してリストに格納
with open(csv_path, mode='r', encoding='utf-8') as f:
reader = csv.DictReader(f)
for row in reader:
json_data.append(row)
# JSON文字列に変換して標準出力へ出力
print(json.dumps(json_data, ensure_ascii=False))
このPythonコードでは、CSVファイルを読み込んで各レコードを辞書形式にし、最終的にJSON文字列として標準出力に書き出しています。先ほどのシェルスクリプトはこの標準出力を受け取ってファイルに保存する仕組みになっています。バッチ処理ではこのように複数のスクリプトやプログラムを組み合わせて一連の処理フローを構成することがよくあります。
なお、上記のシェルスクリプト自体を定期実行するには、Unix系OSであればcron(クロン)と呼ばれるスケジューラに登録します。例えば「毎日深夜2時に実行」するにはcrontabに 0 2 * * * /path/to/convert_csv_to_json.sh のようなエントリを記述します。これによりサーバ上でバッチが自動的にスケジュール実行されるようになります。
ジョブスケジューラの種類と役割
バッチ処理を安定して運用するには、ジョブスケジューラと呼ばれる専用のソフトウェアが用いられることが多いです (バッチ処理で必要となる内部統制課題とは | アシスト)。ジョブスケジューラはバッチジョブの実行タイミングや順序を管理し、実行状況の監視や異常時の再実行制御などを行うツールです。ここでは代表的なジョブスケジューラの例として、以下のものを紹介します。
- cron(クロン):Unix/Linuxに標準搭載されているシンプルなスケジューラです。OSの
crontabにコマンドと実行時間を登録することで、指定時刻にスクリプトやプログラムを実行できます。小規模なバッチやサーバ単体での定時実行にはcronで十分対応可能です。 - JP1/Automatic Job Management System(JP1/AJS):日立製作所が提供するエンタープライズ向けジョブ管理ツールです。国内企業で広く使われており、複数サーバにまたがる大量のバッチジョブを統合的にスケジュール・監視できます。ジョブネットと呼ばれる階層構造でジョブを管理し、依存関係に応じた実行順序制御や画面からの進捗監視が可能です (ジョブ管理とは?ジョブ管理を効率的にするJP1とSHERPA SUITE …) (バッチ処理で必要となる内部統制課題とは | アシスト)。JP1は長年多くの基幹システムで採用されており、専任の運用管理者がいる大規模環境で威力を発揮します。
- Apache Airflow(エアフロー):オープンソースのワークフロー管理ツールで、近年データエンジニアリング分野で人気があります。Pythonでバッチフロー(DAG:有向非巡回グラフ)を定義し、Web UIで実行・監視できます。Airflowはタスク間の依存関係やスケジュールをコードで記述できるため、ETLパイプラインや機械学習バッチなど複雑なワークフローの自動化に適しています。従来型のジョブスケジューラ(JP1やCronなど)が時間主導なのに対し、Airflowはデータ依存のワークフロー表現力が高い点が特徴です。
- Control-M(コントロール・M):BMCソフトウェア社の提供するエンタープライズ向けジョブスケジューラです。こちらもグローバルで古くから使われており、金融機関などミッションクリティカルなシステムで多用されています。異種OSやクラウド環境を含む複雑なバッチ処理を一元管理できるのが強みで、専用のGUIからジョブフローを定義・監視し、詳細な通知やリトライ設定も可能です。長年の実績があるため信頼性が高く、大規模システムのバッチ運用に今なお利用されています。
これら以外にも、富士通のSystemwalkerやIBMのTivoli Workload Scheduler、オープンソースのRundeckやJenkinsなど、多種多様なジョブスケジューラが存在します。いずれにせよ、ジョブスケジューラを活用することでバッチ処理の実行管理が自動化・可視化され、運用担当者は進捗を一画面で把握しやすくなるというメリットがあります (ジョブ管理システムの比較14選。運用管理の規模やOSSを解説 | アスピック|SaaS比較・活用サイト)。特に大量のバッチが稼働する企業システムでは、ジョブスケジューラ無しに人手で実行管理するのは現実的ではないため、適切なツールを選定して導入することが重要です。
バッチ処理設計のポイントと注意点
バッチ処理を設計・実装する際には、リアルタイム処理とは異なる観点で配慮すべきポイントが多数あります (バッチ処理 プラクティス | yamarkz.com)。ここでは、初心者エンジニアやマネージャー層にも押さえておいてほしい主な設計上のポイントと注意点を解説します。
1. 入力データの検証とエラーハンドリング
バッチ処理の入力として使用するデータは、システム内部で生成された信頼できるものとは限りません。他システムから受領したファイルやユーザーがアップロードしたデータなど、内容不備の可能性がある入力については**バッチ処理側でもデータ検証(バリデーション)**を行う必要があります (バッチ設計時の基本的な要点 #新人プログラマ応援 – Qiita)。検証の結果、不正なデータや処理不能なレコードが見つかった場合の対処(エラーハンドリング)方法も重要です。代表的な方式として以下があります。
- (a)即時中断: 1件でもエラーが発生したらバッチ処理全体を途中で停止する方式。データ整合性を厳密に保つ必要がある場合に有効ですが、最後にエラーが見つかるとそれまでの処理をすべてロールバックすることになり非効率です。
- (b)スキップ継続: エラーになったデータのみ飛ばしてバッチ処理自体は最後まで続行する方式。この方式ではスキップしたレコードをログに記録し、後から手動または別途バッチでリカバリできるようにする設計が欠かせません。一方で、エラーが大量にあると結局後処理の手間がかかるため、許容範囲を予め決めておき一定数を超えたら中断する、といった判断基準も必要です。
どの方式を採用するかは業務要件次第です。例えば金融系の振込バッチでは1件の誤りでも全件再処理すべきでしょうし、ログ集計のような処理では多少の不備レコードはスキップして全体を完成させる方が望ましいでしょう。いずれにせよ、エラー発生時にどう振る舞うかを事前に設計し、ログや通知で関係者に分かるようにしておくことが重要です。
2. トランザクション管理とデータ整合性
バッチ処理では大量データをデータベースに読み書きすることが多いため、トランザクション管理の設計も注意が必要です。全件を一括してコミットすれば一貫性は保ちやすいものの、処理時間が長くなるとデータベースのロックが長時間保持され他のオンライン処理に影響を及ぼす可能性があります (バッチ設計時の基本的な要点 #新人プログラマ応援 – Qiita)。一方、細切れにコミットすると処理途中で中断した際にデータが中途半端に書き込まれてしまうリスクがあります。対策としては、適切なコミット間隔やチェックポイントを設計し、長時間ロックによる影響と中途半端コミットのリスクをバランスすることが挙げられます。また、オンライン処理と並行して同じデータを扱う場合は排他制御(ロック)や処理順序にも配慮し、不整合が起きないようにします。例えばバッチ開始前に該当テーブルを締め出す(ロックする)か、あるいは影響を受けないよう別テーブルに書き出して後で入れ替えるなど、システム全体の整合性を考えた設計が必要です。
3. 冪等性(べきとうせい)の確保
冪等性とは同じ処理を何度繰り返し実行しても結果が変わらない性質のことです (バッチ処理 プラクティス | yamarkz.com)。バッチ処理では、途中で障害が発生して再実行するケースや、誤って二重起動してしまうケースなどが考えられます。その際に同じデータを二重反映してしまうと、売上計上が二重になる等の重大な不具合につながります。したがって、バッチ処理は可能な限り冪等に設計することが望ましいです。例えば再実行時には前回処理済みのデータはスキップする、出力先にユニークキー制約を設けて重複挿入が起きないようにする、処理済みフラグやタイムスタンプを使って判定する、といった工夫で冪等性を担保できます。これにより、万一のやり直し時も安心して再実行(リラン)できるようになります。
4. 処理パフォーマンスとスケーラビリティ
バッチ処理は大量データを扱うため、処理時間の見積もりと性能確保も重要です。限られたバッチウィンドウ(実行可能時間内)に処理を終えられない事態、いわゆる「バッチの突き抜け」には注意が必要です (実は身近でも使われているバッチ処理、その概要について解説 | AIZINE(エーアイジン))。対策として、並列処理(データを分割し複数スレッドやプロセスで同時処理する)を取り入れて処理時間を短縮したり、ハードウェアリソースを増強して処理能力自体を高める方法があります。また、巨大なデータセットの場合は一度に全部処理しようとせず、日次・週次など複数バッチに分散させて実行負荷を平準化する戦略も有効です。設計段階で将来のデータ増加も見越し、**「どれくらいの件数・時間まで耐えられるか」**を検証しておくことが望まれます。
5. 可観測性(オブザーバビリティ)とログ
バッチ処理はバックグラウンドで動くため、進捗状況や結果を後から確認できる仕組みを備えることが大切です (バッチ処理 プラクティス | yamarkz.com)。具体的には、処理開始・終了時刻や処理件数、エラー件数などを出力するバッチログを適切に記録し、必要に応じてアラート通知するようにします (ウェブアプリケーション運用に必要な基本的なログについて)。ジョブスケジューラを使っている場合はGUI上で各ジョブの開始・終了ステータスを監視できますが、さらに詳細なアプリケーションログも残しておくと、問題発生時の原因追跡に役立ちます。特にエラーをスキップする設計にしている場合、どのデータが処理されなかったかをログで把握できるようにすることが不可欠です (バッチ設計時の基本的な要点 #新人プログラマ応援 – Qiita)。マネージャークラスの方々はバッチ処理の結果レポート(何件処理され、何件エラーだったか等)を定期的に確認し、問題があれば現場と共有して改善に繋げるようにしましょう。
以上のように、バッチ処理の設計では**「エラーに強く、再実行に耐え、時間内に終わらせる」**ことがキーポイントとなります (バッチ処理 プラクティス | yamarkz.com)。多角的な考慮が必要ですが、予め考えうる課題に対し答えを用意しておくことで安定したバッチ運用が可能になります。
バッチ処理の設計フロー例(擬似コードとフローチャート)
では、上述した設計ポイントを踏まえたバッチ処理の基本的な流れを、擬似コードとフローチャートで簡単に示してみます。
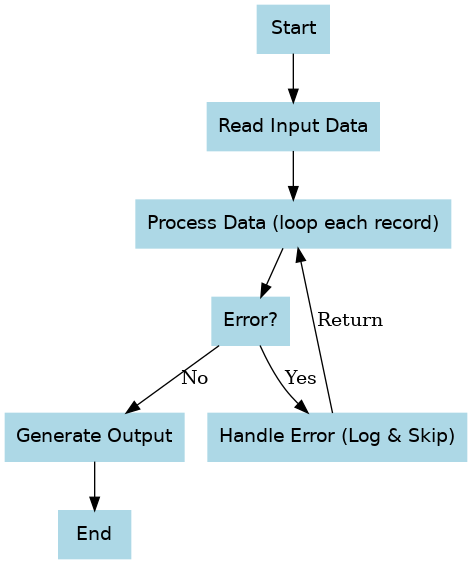
図: バッチ処理ジョブの基本的なフロー例(開始→入力取得→データ処理(繰り返し)→エラー発生時の処理→結果出力→終了)。このフローでは、まず入力データを読み込み、レコードごとに処理を行います。処理中にエラーが発生した場合はエラー内容をログに記録し、そのレコードをスキップして次のレコード処理に進みます(必要に応じて一定数以上のエラーで中断)。全レコードの処理が終わったら結果を出力し、正常終了となります。このようにエラー処理と通常処理の分岐を明確に設計しておくことで、想定外の事態にも対応しやすいバッチ処理となります。
擬似コードで表現すると以下のようになります。
バッチ開始
入力データ = データ源から取得
エラー件数 = 0
繰り返し (入力データの各レコード を 処理対象レコード とする):
処理結果 = 処理対象レコードを処理する
もし 処理結果 がエラーなら:
エラー件数 += 1
エラー内容をログ出力
もし エラー件数 > 許容最大エラー数:
バッチ処理を中断 (異常終了)
終了
次のレコードへ (現在のレコードはスキップ)
それ以外 (正常処理の場合):
正常結果を一時保存
一時保存した結果を出力先へ書き込み
バッチ終了 (正常終了)
上記は簡略化したフローですが、基本的な考え方は実際のバッチ処理と同じです。重要な点は、エラー時の動作(ログ出力・スキップ・中断)を明示的に組み込むこと、そして正常系の処理が継続的に行われ最終結果が出力されることです。現実のバッチ実装ではこの他にも細かな制御(再試行やリソース解放など)が入りますが、大枠の流れはこのようになります。
マネージャーの方はこのフロー図を参考に、現在運用中のバッチ処理がどのような手順を踏んでいるかを担当者に確認してみるとよいでしょう。どこでエラー処理をしているか、ログは十分か、処理時間に無理はないか、といった観点で見直すことで、内部統制上の抜け漏れや将来的なリスクを低減できます。
ビジネス視点での考慮事項(セキュリティ・処理時間・監査ログ 等)
最後に、バッチ処理に関して経営層やマネージャーが押さえておくべきビジネス視点での考慮事項について触れます。技術的な詳細だけでなく、セキュリティや統制、運用管理といった側面からもバッチ処理を理解することが大切です。
●セキュリティと内部統制:バッチ処理にもセキュリティ上の統制が求められます。特に企業の重要データを扱うバッチでは、アクセス権限の管理やデータの機密保持策が不可欠です。例えば、バッチ実行用のIDに過剰な権限を与えすぎない、バッチが出力するファイルには適切なアクセス制限をかけ暗号化も検討する、といった対応です。また、近年は内部統制(J-SOX)の強化により、バッチ処理も含めたIT全般統制の範囲拡大が進んでいます (バッチ処理で必要となる内部統制課題とは | アシスト)。従来は見落とされがちだったバッチ処理ですが、改訂後はクラウドサービス上のバッチやリモート環境での処理も含め、きちんと統制されているか評価対象となり得ます。そのため経営層も、どのようなバッチが社内で動いているか、リスクは何かを把握し、必要ならば運用ルールの整備や監査証跡の確保を指示すべきでしょう。
●処理時間と業務影響:バッチ処理の遅延や失敗は、しばしば業務全体に影響を及ぼします。例えば夜間バッチが予定時刻までに終わらなければ翌朝の業務開始ができない、といった事態も起こり得ます (実は身近でも使われているバッチ処理、その概要について解説 | AIZINE(エーアイジン))。こうしたリスクを踏まえ、バッチの処理時間には常に目を配る必要があります。定期的な処理時間の計測と負荷テストを実施し、余裕度を確認することが重要です。データ量増加によりバッチが徐々に遅延してきた場合は、早めに並列化やハードウェア増強などの対策を検討します。マネージャー層はバッチ処理の所要時間やピーク負荷について定期レポートを受け、ビジネスに支障が出ない範囲で運用できているかレビューするとよいでしょう。
●監査ログと可視化:バッチ処理が適切に行われたことを証明するための監査ログやレポートの整備もビジネス上重要です。誰がいつバッチジョブを実行し、結果がどうであったかを後から追跡できるようにしておくことで、不正や障害発生時にも原因究明と対策がとりやすくなります。ジョブスケジューラの管理画面で確認できる履歴情報に加え、重要なバッチについては実行結果のサマリ(処理件数・エラー件数など)を自動で関係者にメール報告する仕組みも有用です。また、監査対応だけでなく日常の運用としても、可視化されたログ情報は予防保全に役立ちます。ログを分析することでデータ量の増加トレンドが掴め、先手を打って処理のリファクタリングやインフラ増強を計画できるでしょう。
●障害時のリカバリ計画:バッチ処理に100%の成功はなく、いつかは失敗や途中停止が発生するものと想定しておくべきです。ビジネスへの影響を最小に抑えるには、障害発生時の復旧手順(リカバリプラン)を事前に策定しておくことが重要です。具体的には、「途中まで処理した分の扱いをどうするか」「再実行はどの単位で行うか」「代替手段(手動処理など)はあるか」といった観点です。例えば、前半の処理は終わったが後半の集計で失敗した場合、前半結果を残したまま後半だけ再実行できる設計だと迅速に復旧できます。一方で一部データが不完全な状態で残ってしまった場合は、一旦ロールバックして全件再処理する判断が必要かもしれません。こうした判断を現場任せにせず、あらかじめ経営層も交えたビジネス判断基準を決めておくことが望ましいです。たとえば「翌朝9時までに復旧しなければ前日分の売上集計は諦め、次回に持ち越す」など、サービスレベル目標(SLA)に沿った対応方針を定めます。リカバリ計画があれば、いざ障害が起きた際にも関係者が慌てずに対応でき、ビジネスへのダメージを抑えることができます。
●その他の考慮事項:バッチ処理は往々にして古くからのシステムで動いているため、担当者だけでなく組織として知見を保持することも重要です。属人化を避けるためにドキュメントを整備し、新人にも分かる形で処理内容やフロー図を共有しましょう。また、近年はリアルタイム処理やストリーム処理への置き換えも話題になりますが、すべてをリアルタイム化するのが最適とは限りません。コストや必要性を踏まえ、バッチ処理で十分メリットがある部分は残しつつ、即時性が求められる部分だけリアルタイム化するといったハイブリッドなアプローチも有効です (バッチ処理とは? バッチ処理のやり方、メリット、使用例を解説 | Talend)。経営層は最新技術動向も踏まえつつ、自社システムのバッチとリアルタイムの使い分け戦略を考えてみると良いでしょう。
以上、バッチ処理の基礎から業務での活用例、設計上のポイントとビジネス視点での注意事項まで幅広く解説しました。普段目立たない存在ですが、バッチ処理は大量データを陰で支える縁の下の力持ちです。適切に設計・運用すれば、今後も効率的かつ安定したデータ処理手法として企業システムを支えてくれるでしょう (実は身近でも使われているバッチ処理、その概要について解説 | AIZINE(エーアイジン))。ぜひ本記事の内容を参考に、自社のバッチ処理の現状を見直し、より良い運用とビジネス改善に役立てていただければ幸いです。
参考文献・情報源:バッチ処理に関する基本概念や事例について (バッチ処理の基礎-リアルタイム処理との違いにも迫る! | アシスト) (バッチ処理とは – 用途やメリット、課題について – TIBCO|NTTコム オンライン)、バッチ処理設計のベストプラクティスについて (バッチ設計時の基本的な要点 #新人プログラマ応援 – Qiita) (バッチ設計時の基本的な要点 #新人プログラマ応援 – Qiita)、業務上の考慮事項について (バッチ処理で必要となる内部統制課題とは | アシスト) (実は身近でも使われているバッチ処理、その概要について解説 | AIZINE(エーアイジン))など、専門記事や技術ブログ、メーカー提供資料を参照しました。本稿中の引用は各所に示した通りです。









